Dinner Wednesday 28th: meeting at 19:45 in front of Cathédrale Saint Jean, the restaurant is Les Adrets
Registration is open: indico.math.cnrs.fr M3 workshop
Contact: rtca2023@listes.ens-lyon.fr
Mathematical Software and High Performance Algebraic Computing
June 26 to 30, 2023
Location: ENS de Lyon, site Monod, Monod Main entrance.
Practical information (thanks to Nicolas Brisebarre)
Organizers: W. Decker, J.-G. Dumas, C. Pernet, E. Thomé, G. Villard
At present the practical organization of this workshop is partly
prospective since in particular we plan to couple the event with developer days
from various software groups. This ranges from many specialized opensource components (ex: FLINT, FpLLL, LinBox, etc.), to thematic systems (ex: GAP, Pari/GP, Singular, etc.) and general purpose ones (ex: OSCAR, Mathemagix, SageMath, etc.). We also plan to have a participation of MapleSoft and Wolfram Mathematica.
The goal of the workshop is to allow the software actors to present what the existing software systems are, with general and introductory talks, and focus on the latest advances and perspectives.
We also aim at making links between communities by
inviting representatives of interface softwares such as jupyter and Julia, and from research around interoperability formats and OpenMath.
A specific interest will be for the advancement of optimized code and parallel software in all areas of symbolic mathematical computation. Research challenges also concern interfaces and integration of components, JIT compilation and metaprogramming. At the algorithmic and application level, mastering precisions and hybrid symbolic, certified and numerical methods requires complex environments and sophisticated software implementations. New applications, computational challenges and experimental mathematics problems should be raised to open up new perspectives for the design of computer algebra softwares.
Preliminary Program
| Monday June 26th, 2023 - Site Monod, Amphi H, ground floor north, main building | ||
|---|---|---|
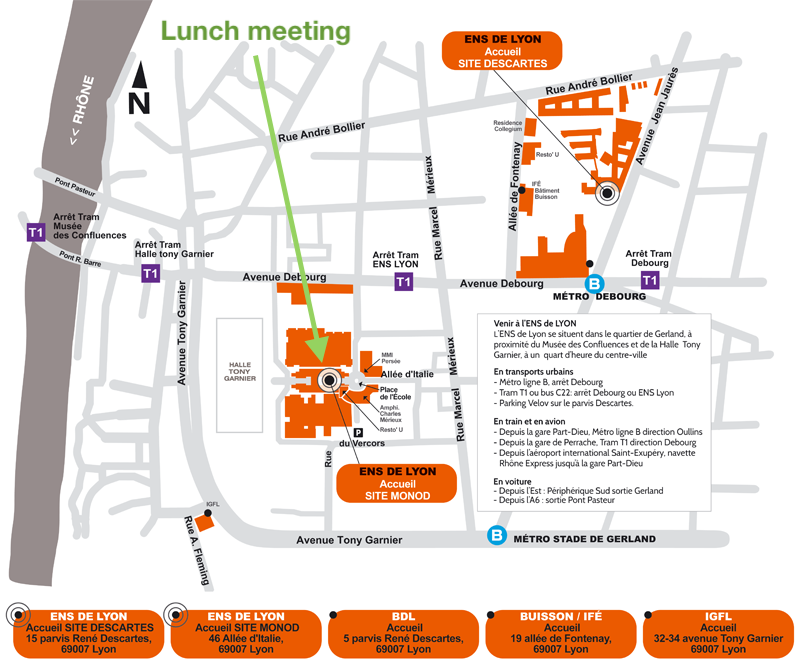
| 12:30-13:45 | Lunch: meeting at 12:20 just outside the main ENS entrance, map here | |
| 13:45-14:00 | Opening | |
| 14:00-15:00 | Fredrik Johansson | FLINT: Fast Library for Number TheoryFLINT is a C library concerned mainly with efficient arithmetic in basic rings like $\mathbb{Q}[x]$, used in SageMath, Oscar, and elsewhere. We give a brief introduction to FLINT and discuss its current strengths and weaknesses for high performance algebraic computing. We will also present the upcoming FLINT 3.0 release. Notable changes include a new vectorized small-prime FFT, a C implementation of generic rings, and merging with the Arb, Calcium and Antic libraries. |
| 15:00-16:00 | Bill Allombert | PARI/GP, toward high performance computing for number theoristsPARI/GP was initiated in 1986 as one of the first computer algebra system dedicated to number theory, and its goal was to enable mathematicians to use computers to perform advanced computations. More recently, we extended PARI/GP to support distributed computing, using either POSIX threads or MPI, for some of the algorithms implemented in PARI/GP and also for user programs written in the GP script language to allow mathematicians to take advantage of parallelism without requiring a background in parallel programming. We give an overview of the underlying technics, interfaces and algorithms. |
| 16:00-16:30 | Coffee break | |
| 16:30-17:30 | Nicolas Thiéry | 60 years of libre scientific softwareFor decades, Libre software has had a deep and fruitful relationship with research, as tool, outcome, or object of study. Painting an exhaustive landscape in a few tens of minutes will be a task for historians, especially so since the needs and practices greatly vary from one field to the other. In this talk, we will simply highlight some fundamental trends -- typology of software, development and funding models -- from a personal perspective, with the aim to trigger experience sharing among participants. |
| 12:00-19:00 | Dedicated work room M7, 3rd floor | |
| Tuesday June 27th, 2023 - Site Monod, Amphi B, 3rd-4th floor, main building | ||
| 9:00-10:00 | Keegan Ryan | Fast Practical Lattice Reduction through Iterated CompressionWe introduce a new lattice basis reduction algorithm with approximation guarantees analogous to the LLL algorithm and practical performance that far exceeds the current state of the art. We achieve these results by iteratively applying precision management techniques within a recursive algorithm structure and show the stability of this approach. We analyze the asymptotic behavior of our algorithm, and show that the heuristic running time is $O(n^{\omega}(C+n)^{1+\varepsilon})$ for lattices of dimension $n$, $\omega\in (2,3]$ bounding the cost of size reduction, matrix multiplication, and QR factorization, and $C$ bounding the log of the condition number of the input basis $B$. This yields a running time of $O\left(n^\omega (p + n)^{1 + \varepsilon}\right)$ for precision $p = O(\log \|B\|_{max})$ in common applications. Our algorithm is fully practical, and we have published our implementation. We experimentally validate our heuristic, give extensive benchmarks against numerous classes of cryptographic lattices, and show that our algorithm significantly outperforms existing implementations. |
| 10:00-11:00 | Wolfram Decker | OSCAR - A new Computer Algebra SystemThe OSCAR project develops a comprehensive Open Source Computer Algebra Research system for computations in algebra, geometry, and number theory, with particular emphasis on supporting complex computations which require a high level of integration of tools from different mathematical areas. The project builds on and extends the four cornerstone systems GAP, Singular, polymake, and Antic, as well as further libraries and packages, which are combined using the Julia language. Though still under development, OSCAR is already usable. In this talk, I will give examples of what is possible right now, and outline future lines of development. |
| 11:00-11:30 | Coffee break | |
| 11:30-12:30 | Emmanuel Thomé | Cado-NFS, a versatile software platform for the Number Field SieveThe Cado-NFS software was used in the latest computational records for integer factoring and the computation of discrete logarithms in finite fields. Beyond that, it is also a rather versatile piece of software whose building blocks can be used in many similar computations. This talk will describe both the general context of the Number Field Sieve as well as the specifics of the Cado-NFS implementation, and highlight to which extent it can be used as a research platform for the investigation of variations of this algorithm for other purposes. |
| 12:30-14:00 | Lunch break | |
| 14:00-15:00 | Joris van der Hoeven | Fast multiplication of sparse polynomialsWe will present a recent algorithm for the efficient multiplication of sparse multivariate variables and discuss some of the implementation aspects. |
| 15:00-16:00 | Aurel Page | PARI/GP, playing the L-functions game of number theoristsThere is a popular game among number theorists: to construct certain series ("L-functions") from various objects and to see if they coïncide. This game even has a fancy name: the "Langlands programme". We will show how to play this game with PARI/GP, and use it as a pretext to present some recent and some future features of PARI/GP. |
| 16:00-16:30 | Coffee break | |
| 16:30 | Sprint | |
| 12:00-19:00 | Dedicated work rooms B1 and B2, 4th floor | |
| 16:00-19:00 | Dedicated work room M7, 3rd floor | |
| Wednesday 28th, 2023 - Site Monod, Amphi B, 3rd-4th floor, main building | ||
| 9:00-10:00 | Anna Maria Bigatti | The design of CoCoALib/CoCoAFirst released in 1988, CoCoA is a special-purpose system for doing Computations in Commutative Algebra. It is freely available under GPL, and offers CoCoALib, the C++ library, which is the mathematical heart; a computation server; and CoCoA-5, the interactive system. |
| 10:00-11:00 | Claus Fieker | Number Theory in Oscar: Class Groups, Class Fields and BeyondIn this talk, I'll introduce the number theory module of Oscar, starting from the basics like number fields, ring of integers and ideals to class groups, class fields, Galois theory and Galois cohomology. |
| 11:00-11:30 | Coffee break | |
| 11:30-12:30 |
|
|
| 12:30-14:00 | Lunch break | |
| 14:00-15:00 | Anton Leykin | Macaulay2: High Performance Algebraic ComputingThe computer algebra system Macaulay2 (M2) was initially designed to appeal to commutative algebraists and algebraic geometers. In its more than 30 years of existence M2 attracted mathematicians and computer scientists coming from many neighboring areas. Many of them have appetite for resource-intensive casework of various kinds: one typical use case for M2 is to search for examples or counterexamples over large families of mathematical objects. |
| 15:00-16:00 | Jean-Guillaume Dumas | libVESPo, a C++ library for the Verified Evaluation of Secret Polynomials & Dynamic proofs of retrievabilityProofs of Retrievability are protocols which allow a Client to store data remotely and to efficiently ensure, via audits, that the entirety of that data is still intact. Dynamic Proofs of Retrievability (DPoR) also support efficient retrieval and update of any small portion of the data. We propose a novel protocol for arbitrary outsourced data storage that achieves both low remote storage size and audit complexity. A key ingredient, that can be also of intrinsic interest, reduces to efficiently evaluating a secret polynomial at given public points, when the (encrypted) polynomial is stored on an untrusted Server. The Server performs the evaluations and also returns associated certificates. A Client can check that the evaluations are correct using the certificates and some pre-computed keys, more efficiently than re-evaluating the polynomial. Our protocols support two important features: the polynomial itself can be encrypted on the Server, and it can be dynamically updated by changing individual coefficients cheaply without redoing the entire setup. We present in this talk some implementations of these methods, using linearly homomorphic encryption and pairings, and show good performance for polynomial evaluations with millions of coefficients, and efficient distant (e.g. transatlantic) DPoR with terabytes of data. |
| 16:00-16:30 | Coffee break | |
| 16:15-17:15 | Michael L. Overton | AriC Seminar
Crouzeix’s ConjectureCrouzeix’s conjecture is among the most intriguing developments in matrix theory in recent years. Made in 2004 by Michel Crouzeix, it postulates that, for any polynomial \(p\) and any matrix A , \(\|p(A)\| \le 2 \max\{|p(z)|: z \in W(A)\}\), where the norm is the 2-norm and \( W(A) \) is the field of values (numerical range) of \(A\), that is the set of points attained by \( v^*Av \) for some vector \(v\) of unit length. Crouzeix proved in 2007 that the inequality above holds if \(2\) is replaced by \(11.08\), and in 2016 this was greatly improved by Palencia, replacing \( 2 \) by \( 1+\sqrt{2} \). Furthermore, it is known that the conjecture holds in a number of special cases. We use nonsmooth optimization to investigate the conjecture numerically by locally minimizing the “Crouzeix ratio”, defined as the quotient with numerator the right-hand side and denominator the left-hand side of the conjectured inequality. We use Chebfun to compute the boundary of the fields of values and BFGS for the optimization, computing the Crouzeix ratio at billions of data points. We also present local nonsmooth variational analysis of the Crouzeix ratio at conjectured global minimizers. All our results strongly support the truth of Crouzeix’s conjecture. |
| 16:30 | Sprint | |
| 12:00-19:00 | Dedicated work rooms B1 and B2, 4th floor | |
| 14:00-19:00 | Dedicated work room 316 centre, 3rd floor | |
| 19:45 | Meeting for dinner | |
| Thursday 29th, 2023 - Site Monod, Amphi B, 3rd-4th floor, main building | ||
| 9:00-10:00 | Luca De Feo | SQIsign, the number theorists' great crypto heistSince forcing everyone to switch to elliptic curve cryptography, computational number theorists have spun out of control and now feel entitled to dump their crazy sh..eaves on the world. |
| 10:00-11:00 | François Lemaire | The Differential Algebra projectThe DifferentialAlgebra project, lead by François Boulier, aims at providing BLAD, a C library dedicated to Ritt and Kolchin differential algebra, and BMI, a library providing interface packages for various scientific computing software such as Maple, Sagemath, Python / Sympy... Recent functionalities will be presented through several applications of differential algebra technics (quasi-equilibrium approximation, fraction decoupling, ...). URL: https://codeberg.org/francois.boulier/DifferentialAlgebra |
| 11:00-11:30 | Coffee break | |
| 11:30-12:30 | Marc Moreno Maza | Contributions to Automatic Parallelization, Probably in Support of Computer AlgebraParallelization usually refers to the activity of the programmer who is applying the fork-join pattern to divide-and-conquer algorithms, or who is turning a for into parallel-for. In contrast, automatic parallelization usually refers to the techniques that an optimizing compiler implements for exposing parallelism (dependence analysis, tiling, loop transformations, etc.), scheduling tasks (load balancing, reducing parallelism overheads, etc.) and generating parallel code (allocating resources, in particular memory). |
| 12:30-14:00 | Lunch break | |
| 14:00-15:00 | Mohab Safey El Din | Polynomial system solving with the msolve librarySolving multivariate polynomial systems arises in a wide range of areas in information theory (e.g. cryptography, error-correcting codes) to engineering sciences (e.g. robotics, biology). The msolve library is a C library which provides implementations of a number of algorithms based on Gröbner bases computations for its algebraic component and bisection algorithms for real root isolation. We will present its design, its current capabilities and discuss further developments. |
| 15:00-16:00 | Pascal Giorgi | LinBox: a generic high performance library for exact linear algebraLinear algebra is an important tool in nowadays mathematical computations that are supported by many general purpose software: Maple, Mathematica, Sagemath, Pari/GP, etc. The LinBox project, initiated in the late '90s, aims to provide efficient tools for exact linear algebra computations, notably over finite fields, integers, rational numbers or polynomials. The project develops three libraries to support this goal: Givaro, FFLAS-FFPACK and LinBox. In this talk, we will provide a general presentation of these libraries to emphasize what a user could expect from them and which design evolution was necessary to obtain efficient generic codes. We will also discuss some of the algorithmic reductions that have deeply contributed to provide high performance libraries in practice. |
| 16:00-16:30 | Coffee break | |
| 16:30 | Sprint | |
| 8:00-19:00 | Dedicated work room 316 centre, 3rd floor | |
| 12:00-19:00 | Dedicated work rooms B1 and B2, 4th floor | |
| Friday 30th, 2023 - Site Monod, Amphi B, 3rd-4th floor, main building | ||
| 9:00-10:00 | Gleb Pogudin | Software for structural parameter identifiabilityIn a parametric ODE model, a parameter is called structurally identifiable if its value can be uniquely determined from the input-output data, assuming the absence of noise and sufficiently exciting inputs. This identifiability property is a natural prerequisite for practical parameter estimation, and, therefore, it is an important step in the experimental design process. The problem of assessing identifiability has been studied since the 70-s and several approaches, all relying at least partially on computer algebra, have been proposed. At the moment there are at least a dozen software tools to assess different types of structural identifiability. I will talk about three of them in the development of which I have been involved: SIAN written in Maple, web-based Structural Identifiability Analyzer, and StructuralIdentifiability.jl. I will describe the algorithms and design decisions behind these tools, current challenges and future plans, and some experience of interactions with the end users who are typically far outside of the computer algebra community. |
| 10:00-11:00 | Jean-Yves L'Excellent | Sparse direct solvers and HPCThe solution of sparse systems of linear equations is a key computational kernel in scientific computing. It often represents the most time, memory and energy consuming part of the whole numerical simulation process. Therefore, it is critical to design efficient sparse solvers. In this talk, we focus on sparse direct solvers, which are well-known for their numerical robustness and accuracy. We present recent key features of sparse direct solvers that enable to efficiently solve large real and complex systems, and that have led to a strong gain of interest of these methods in many applications. We also illustrate how today challenges related to heterogeneity of computers, energy control, mixed-precision arithmetics, new models and applications, motivate new research in the field of sparse direct solvers. We finally mention how the sparse direct solver MUMPS is supported by research and industrial collaborations. |
| 11:00-11:30 | Coffee break | |
| 11:30-12:30 | Max Horn | GAP: Past, present, futureGAP is an open source computer algebra system with a focus on discrete algebra, specifically group theory and combinatorics, with its own high-level programming language. It was initiated in 1985 in Aachen, and has received many contributions from around the globe over the years. Most recently its development is being coordinated from Kaiserslautern, in close collaboration with the OSCAR project, of which it is an integral part. Keeping a research software project alive and relevant is a serious challenge. We will discuss some aspects of what makes and breaks this. A possible way forward for GAP is sketched that involves basing its core on Julia, via the standalone bidirectional GAP-Julia bridge developed in OSCAR. As a demonstration we will explain how we adapted theGAP package "Alnuth" to use OSCAR's number theory capabilities. |
| 12:30-14:00 | Lunch and end of the workshop |
{kind=link}